概览
众所周知,分类问题是数据挖掘领域的主要任务之一,并已经发展出了大量成熟且实用的分类算法。
但需要注意到的是,这一类的传统分类算法,它们通常以数据类分布大致平衡为前提,并以降低分类错误率(ErrorRate)提高精度(accuracy)作为分类模型的优化目标。
事实上,在实际应用中,常常有大量分类问题都是不平衡的,这导致其难以直接应用于不平衡学习。比如说对于一个数据集,其正负样本比例为500:1(在网络攻击识别、信用卡欺诈检测中这样的比例是非常常见的,甚至还会远大于此,比如正负样本比例达到10000:1)
那么如果模型得出的混淆矩阵如图——
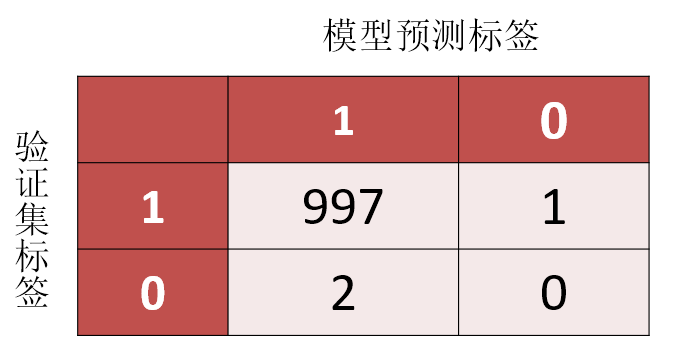 我们可以知道:
我们可以知道:
验证集的标签比例是1:0 = 998:2
而模型预测,即便对于我们真正想找出的、只有2个值的0这个异常标签,一个都没有预测正确。但是其精度依然可以达到0.997
而在实际情况中,0这个标签可能是病情检测场景下,代表患者患癌症的标签,或是网络攻击场景中,代表恶意攻击的标签。这样的分类结果显然是不可接受的。因此,传统分类算法几乎无法适应不平衡分类问题。
在过去20余年里,学者们在不平衡分类问题的处理上展开了大量深入的探索与研究。
从处理层面上看,这些方法大多从3个层面入手——
- 数据层面:改变数据的分布
- 算法层面:设计新的分类方法
- 模型评估层面:设计新的分类器性能评估准则
从本质上看,几乎所有不平衡学习算法都在调整和控制四个核心影响因素——
- 训练集大小(training set size)
- 类优先级(class priors)
- 类别误分代价(cost of errors in different classes)
- 决策边界的设置(placement of decision boundaries)
以下将根据处理层面上的分类,分别讨论处理不平衡分类问题的一些主流思路算法。
数据层面——重采样
需要注意的是,bootstrap, bagging 和 adaBoost是使用重采样的有监督学习方法。相似的,当与其他用来训练分类器的算法结合使用时,其他的重采样方法也被设计来提高分类器的精度。比如说,重采样经常被建议在不平衡数据集中采用。 重采样通过使用人工机制将样本添加到少数类或减少不平衡数据集的多数类,从而使得重采样后的数据分布更接近平衡的数据分布。
重采样的方法可以被分为以下几组——
- 随机过采样(random oversampling)和欠采样(under-sampling)
- informed undersampling
- 综合采样synthetic sampling with data generation
其中——
欠采样通过减少多数类中样本数量来使数据集恢复平衡,但是可能会导致多数类中的信息丢失。 过采样则通过增加少数类中样本数量来使数据集恢复平衡,但是可能会导致过拟合。 综合采样通过使用聚类的方法为少数类生成综合数据样本,比如说找到当前的少数类的近邻。这个方法可能会导致增加两个类之间的重叠率。
尽管没有十全十美的方法,研究表明,对于不平衡数据集,重采样能有效提高分类器的综合分类表现。
过采样
SMOTE算法
欠采样
- One—sided selectio
- GA
- 基于聚类
算法层面
- 代价敏感学习器(cost-sensitive learners)
- 单类学习器(one-class learners)
- 集成方法(ensemble methods)
- 面向单个正类的FLDA方法
- 多类数据不平衡问题的解决方法
- 其他方法 *主动学习、半监督、随机森林、子空间方法、特征选择方法和SVM模型下的后验概率求解方法等。
代价敏感学习器
在误分类代价不同的情况下,代价敏感学习器最大化一个损失函数,这个损失函数和基于数据的代价矩阵相关。 而代价敏感的方法就是提升了不平衡数据下的分类表现,虽然它是基于能获得这个代价矩阵的假设下的。
单类学习器
单类学习器被训练来在从一个类中识别出样本的同时拒绝另一个类的样本。在训练过程中,单类数据主要被用来成功识别占少数比例的类。单类学习器不稳定,并且其表现极大程度上被使用的参数和内核所影响。
集成方法
集成机器学习采用一种合适的方法,将多种分类器的分类结果集结到唯一一个分类结果中,比如说投票(voting)。这个方法尝试通过训练独立的模型来泛化任务,对于这些独立模型而言,他们的训练集会从整个数据集中随机选取。只要每个数据子集不同,集合方法就可以很好地发现机器学习任务。
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类——
- 个体学习器间存在强依赖关系,必须串行生成的序列化方法 代表方法:Boosting
- 个体学习器间不存在强依赖关系、可同时生成的并行化方法 代表方法:bagging和随机森林(Random Forest)
在bagging集成中,每个分类器都使用数据集的一个不同的bootstrap来进行训练。 平均bootstrap包含约62%源数据。一旦所有的分类器都被训练完成,最终的分类结果便通过计算这些分类器的投票结果来得出最终分类结果。 当单个分类器能够识别训练集的分类中的巨大差异的时候,bagging表现得很好。
bootstrap则用于权衡那些最容易被误分类的样本。在bootstrap里,误分类的概率上升,对于那一系列的分类器而言,反之亦然。
集合分类器只有在分类器之间存在分歧的时候才有效,并且分类器的组合并不能保证他们比单个分类器拥有更好的性能。
其他方法
半监督
此外,研究人员还尝试采用半监督的机器学习方法来应对有监督学习中的挑战,例如时间消耗(time consumption),费用(expensivences),专业知识的限制以及收集标签数据时标签的准确性。值得一提的是,半监督学习在网络异常检测中同样具有相应的应用(Lakhina 等,2004)。
强化学习
强化学习(Reinforce learning)是机器学习的一个分支,它通过考虑环境中有限状态的反馈,以适应环境中的行动。在安全领域里,强化学习方法尤其适用于网络基础设施的多代理环境。你可以查看这篇论文( Kaelbling et al.,1996; Chapelle et al.,2006)来对半监督学习了解更多详情。
特征选择
模型评估层面
精度(Accuracy)和错误率(ErrorRate)
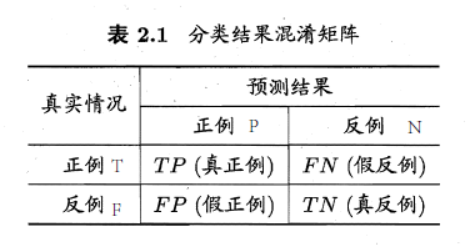 其中
其中
TP代表真实标签为TRUE而判断为positive的样本数(true positive,真正例)
FP代表真实标签为FALSE而判断为positive的样本数(false positive,假正例)
FN代表真实标签为TRUE而判断为negative的样本数(true negative,假反例)
TN代表真实标签为FALSE而判断为negative的样本数)(false negative,真反例)
精度Accuracy和错误率ErrorRate分别有以下定义: $$Accuracy=\frac{TP+TN}{TP+TN+FP+FN}$$ $$ErrorRate=1-Accuracy$$
准确率(Presicion)和召回率(Recall)
如前所述,对于500:1比例的正负样本集而言,即便负样本全部分错,模型精度也可以达到0.997,因此光凭借精度和错误率已无法满足我们对模型进行有效评估了。
基于以上的混淆矩阵,目前常通过这几个评估指标来对不平衡学习算法进行评估—— $$准确率 Precision=\frac{TP}{TP+FP}$$ $$召回率 Recall=\frac{TP}{TP+FN}$$ $$特异度 Specificity=\frac{TN}{TP+FN}$$
- Precision表征分类预测的精准程度——在所有预测为positive的样本中,正确分类的比例;
- Recall表征分类算法对positive类预测的完整性——在所有实际positive的样本中,被正确预测的比例。 PS. 准确率Precision偶尔也被称为敏感度sensitivity或命中率hit rate
Precision对类别分布的变化敏感,而Recall反之。 根据上式,不平衡分类问题的目标简化为:在不影响Precision的前提下,尽可能提高Recall。但由于Precision与Recall的反向关系,实现上述问题显然需要一定权衡。
误分类率Misclassification Rate
$$误分类率Misclassification Rate=\frac{FN+FP}{TP+FP+TN+FN}$$ 在评估真实和预测的分类率之间的不一致概率的时候,误分类率很有用。
PR(Precision-Recall) curve图
根据学习器的预测结果对样例进行排序,排在前面的是学习器认为"最可能"是正例的样本,排在最后的则是学习器认为"最不可能"是正例的样本.按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的准确率和召回率。
以准确率为纵轴、召回率为横轴作图,就得到了准确率-召回率曲线,简称" P-R 曲线",显示该曲线的图称为" P-R图" 图。
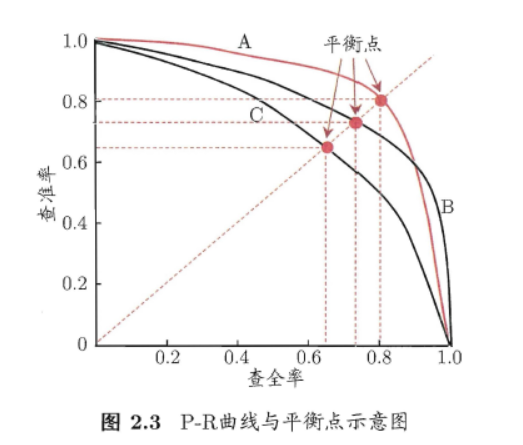
P-R 图直观地显示出学习器在样本总体上的召回率、准确率。 在进行比较时,若一个学习器的P-R 曲线被另一个学习器的曲线完全"包住" ,则可断言后者的性能优于前者,例如图2.3中学习器A 的性能优于学习器C; 如果两个学习器的P-R 曲线发生了交叉。例如图2.3中的A与B,则难以一般性地断言两者孰优孰劣,只能在具体的准确率或召回率条件下进行比较。然而,在很多情形下,人们往往仍希望把学习器A与B比出个高低. 这时一个比较合理的判据是比较P-R曲线节面积的大小,它在一定程度上表征了学习器在准确率和召回率上取得相对"双高"的比例.但这个值不太容易估算, 因此人们设计了一些综合考虑准确率、召回率的性能度量.
平衡点、F值和G-Measure
“平衡点” (Break-Event Point,简称BEP)就是这样一个度量,它是$$准确率=召回率$$时的取值,如图2.3中学习器C的BEP是0.64,而基于BEP的比较,可认为学习器A优于B。 但BEP还是过于简化了些,更常用的是F1度量: $$F1=\frac{2 \cdot Precision \cdot Recall}{Precision \cdot Recall}=\frac{2 \cdot TP}{样例总数+TP-TN}$$ 在一些应用中,对准确率和召回率的重视程度有所不同.例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时准确率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时召回率更重要. F1 度量的一般形式$F_{\beta}$能让我们表达出对准确率/召回率的不同偏好,它定义为 $$F_{\beta}=\frac{(1+\beta)^2 \cdot Recall \cdot Precision}{\beta^2 \cdot Recall+Precision}$$ 其中$\beta>O$ 度量了召回率对准确率的相对重要性[Van Rijsbergen, 1979].
- $\beta = 1$时退化为标准的F1;
- $\beta > 1$时召回率有更大影响;
- $\beta < 1$时准确率有更大影响.
$F_{\beta}$是一种典型的权衡函数,它对数据集上类别分布的变化仍然敏感,其中参数$\beta$调整Presicion和Recall在不同应用背景下的比重,整体描述了分类算法的表现。另一种权衡函数是G-mean,同样可以刻画算法性能,且对类别分布的变化不敏感。
$$G-mean=\sqrt{\frac{TP}{TP+FN} \times \frac{TN}{TN+FP}}$$
尽管以上四个评估指标与Accuracy和ErrorRate相比,描述能力有巨大提高,但是它们只能刻画某一个分类器在某一种特定类别分布下的性能,能力仍然是有限的。
ROC和AUC
很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与一个分类阔值(threshold)进行比较,若大于阈值则分为正类,否则为反类.例如,神经网络在一般情形下是对每个测试样本预测出一个[0.0, 1.0] 之间的实值,然后将这个值与0.5 进行比较,大于0.5 则判为正例,否则为反例.这个实值或概率预测结果的好坏,直接决定了学习器的泛化能力.实际上,根据这个实值或概率预测结果,我们可将测试样本进行排序,“最可能"是正例的排在最前面,“最不可能"是正例的排在最后面.这样,分类过程就相当于在这个排序中以某个"截断点” (cut point)将样本分为两部分,前一部分判作正例,后一部分则判作反例.
在不同的应用任务中,我们可根据任务需求来采用不同的截断点,例如若我们更重视"查准率”,则可选择排序中靠前的位置进行截断;若更重视"查全率",则可选择靠后的位置进行截断.因此,排序本身的质量好坏,体现了综合考虑学习器在不同任务下的"期望泛化性能"的好坏,或者说"一般情况下"泛化性能的好坏. ROC 曲线则是从这个角度出发来研究学习器泛化性能的有力工具.
ROC 全称是"受试者工作特征" (Receiver Operating Characteristic) 曲线.它源于"二战"中用于敌机检测的雷达信号分析技术,二十世纪六七十年代开始被用于一些心理学、医学检测应用中,此后被引入机器学习领域[Spackman, 1989]. 与前面介绍的P-R 曲线相似,我们根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标作图’就得到了"ROC 曲线。与P-R曲线使用准确率、召回率为纵、横轴不同, ROC 曲线的纵轴是"真正例率" (True Positive Rate,简称TPR) ,横轴是"假正例率" (False Positive Rate,简称FPR) ,两者分别定义为
$$TPR=\frac{TP}{TP+FN}$$
$$FPR=\frac{FP}{TN+FP}$$
显示ROC 曲线的图称为"ROC图".图2.4(a)给出了一个示意图,显然,对角线对应于"随机猜测" 模型,而点(0,1) 则对应于将所有正例排在所有反例之前的"理想模型"
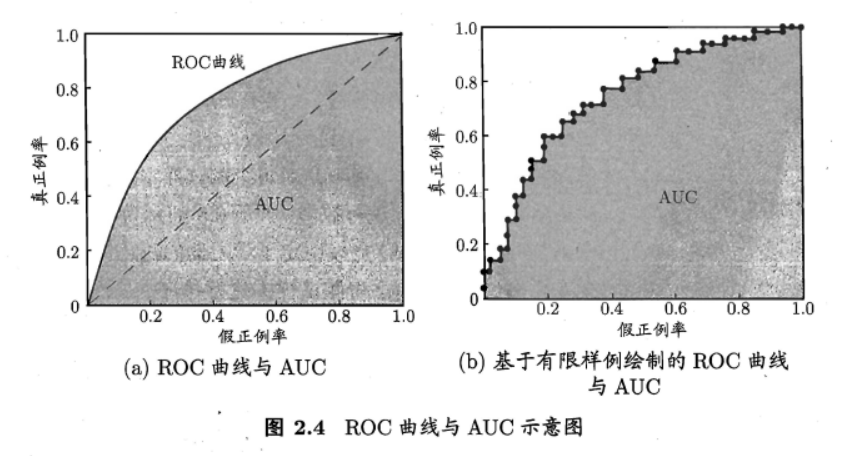
(AUC待补充)
cost curve图
一些别的学习资料
References
Data Mining and Machine Learning in Cybersecurity
Network Anomaly Detection
Haibo He,el.Learning from Imbalanced Data
周志华.机器学习.
陈晶.不平衡分类学习综述.
李勇el,.不平衡数据的集成分类算法综述.2014
杨明,等:不平衡数据分类方法综述.2008

