P.S. 鉴于个人水平有限,若有表述错误之处敬请指出,愿我们共同进步~
基本型推导
SVM一直是我非常喜欢的一个算法,所以没事喜欢推一推。 这里尝试用简单直白的语言来对它的推导过程进行介绍~如果你已经把高数和高中数学忘得差不多了,我想这或许就是你一直在找的简明SVM推导过程介绍~😋
给定$D={(x_1,y_1),(x_2,y_2),…,(x_m,y_m)},y_i \in {-1,+1}$,SVM考虑基于训练集$D$在样本空间中找到一个划分超平面(hiperplane),将不同类别的样本分开。
划分超平面公式: $${\bf \omega}^Tx+b=0 \tag{1.1}$$ (别慌,它其实就是一条直线公式而已) 其中$\omega=(\omega_1;\omega_2;…;\omega_d;)$为法向量,决定了超平面的方向;$b$为位移项,决定了超平面与原点之间的距离。通常划分超平面用$(\omega,b)$来表示,因为其可被法向量$\omega$和位移$b$确定。 样本空间中任意点$x$到超平面$(\omega,b)$的距离可写为 $$r=\frac{|\omega^Tx+b|}{||\omega||} \tag{1.2}$$ (再次别慌,让我们转动我们掌握了初中数学知识的小脑瓜来想一下,其实这就是点到直线的距离公式对吧) 假设超平面$(\omega,b)$能将训练样本正确分类,对于$(x_i,y_i)\in D$,有以下式子: $$\begin{cases}\omega^Tx_i+b > 0, & y_i = +1\\omega^Tx_i+b < 0, & y_i = -1\end{cases} \tag{1.3}$$ 这其实便是 逻辑回归 的思路,非黑即白,但是这明显对自己的算法太自信了,我们可爱的支持向量机对此表示怀疑,并多留了一个心眼,于是它令: $$\begin{cases}\omega^Tx_i+b \geq +1, & y_i = +1\\omega^Tx_i+b \leq -1, & y_i = -1\end{cases} \tag{1.4}$$
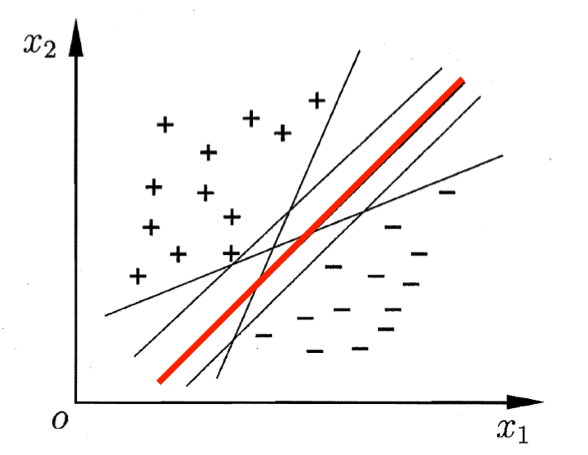
如图所示:
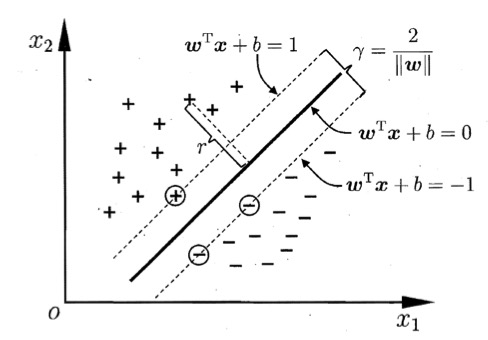
其中距离超平面最近的几个训练样本点使上式的等号成立,这几个训练样本就被称作支持向量(support vector),两个异类支持向量到超平面的距离之和,也称为间隔(margin),为 $$\gamma = \frac{2}{||\omega||} \tag{1.5}$$ (其实就是 $\omega^Tx_i+b = +1 $和$ \omega^Tx_i+b = -1 $两条直线之间的距离公式)
那么按我们的设想,我们做分类学习,实际上就是为了找到一个划分超平面将这些样本给隔开,那么什么样子的划分超平面是最有效的呢? 从直观上来看,位于正负样本“正中间”的划分超平面,也就是上上图红色的那一个划分超平面,应该是最好的,因为它的鲁棒性最好,对未知样本的泛化性最好。
那么如何去得到这个刚好位于正负样本“正中间”的划分超平面呢?
思考一下,是不是只要我们让间隔最大,这样只要我们取间隔中间的那条直线,我们就可以找到这个最棒的划分超平面了? 换句话说,对于基于SVM的分类学习而言,问题已经从找到一个最好的划分超平面转换为了找到样本空间里的最大化间隔。 我们用数学语言来描述一下这个更新后的问题,就变成了找到能满足$式(1.4)$的约束条件的参数$\omega$和$b$,并且要使得$\gamma = \frac{2}{||\omega||}$中的$\gamma$最大。 用数学公式来表示是这个样子。 $$max_{\omega,b} \frac{2}{||\omega||},s.t. y_i(\omega^Tx_i+b) \geq 1, i = 1,2,…,m \tag{1.6}$$ OK,你可能会喊:
等等等等,$max_{\omega,b} \frac{2}{||\omega||}$是表示$\max \gamma$我懂,但是你这个条件$y_i(\omega^Tx_i+b) \geq 1, i = 1,2,…,m$是什么鬼你要不要解释一下?
嗯咳,让我们暂停一下,回看一下约束条件: $$\begin{cases}\omega^Tx_i+b \geq +1, & y_i = +1\\omega^Tx_i+b \leq -1, & y_i = -1\end{cases} \tag{1.4}$$ 注意,是不是上下两个约束条件的左右式子相乘($ \omega^Tx_i+b \geq +1 * y_i = +1$ or $\omega^Tx_i+b \leq -1 * y_i = -1$ )就等于$y_i(\omega^Tx_i+b) \geq 1$了?
OK,让我们继续往下。对于式子 $$max_{\omega,b} \frac{2}{||\omega||},s.t. y_i(\omega^Tx_i+b) \geq 1, i = 1,2,…,m \tag{1.6}$$ 显然,为了最大化间隔,仅需最大化$\frac{1}{||\omega||}$,这等价于最小化$||\omega||^2$。于是上式我们可以重写为 $$min_{\omega,b}\frac{1}{2}||\omega||^2,s.t. y_i(\omega^Tx_i+b) \geq 1, i = 1,2,…,m \tag{1.7}$$ 这就是SVM的基本型。
凸二次规划问题
$$min_{\omega,b}\frac{1}{2}||\omega||^2,s.t. y_i(\omega^Tx_i+b) \geq 1, i = 1,2,…,m \tag{1.7}$$ 在我们开始对这个式子进行求解之前,首先我们需要注意到,它其实是一个凸二次规划问题(convex quadratic programming)。 等等,你可能会问,什么叫做凸二次规划问题? (下方涉及较为复杂的数学表达,非战斗人员请迅速撤离现场。如果你已经做好了心理准备,请扛上草稿本和我一起来~)
凸集
在讲凸二次规划问题之前,我们需要介绍一些更细致的定义。 首先是凸集,几何意义如图所示,指集合中任意两点间的线段永远在集合中的集合。
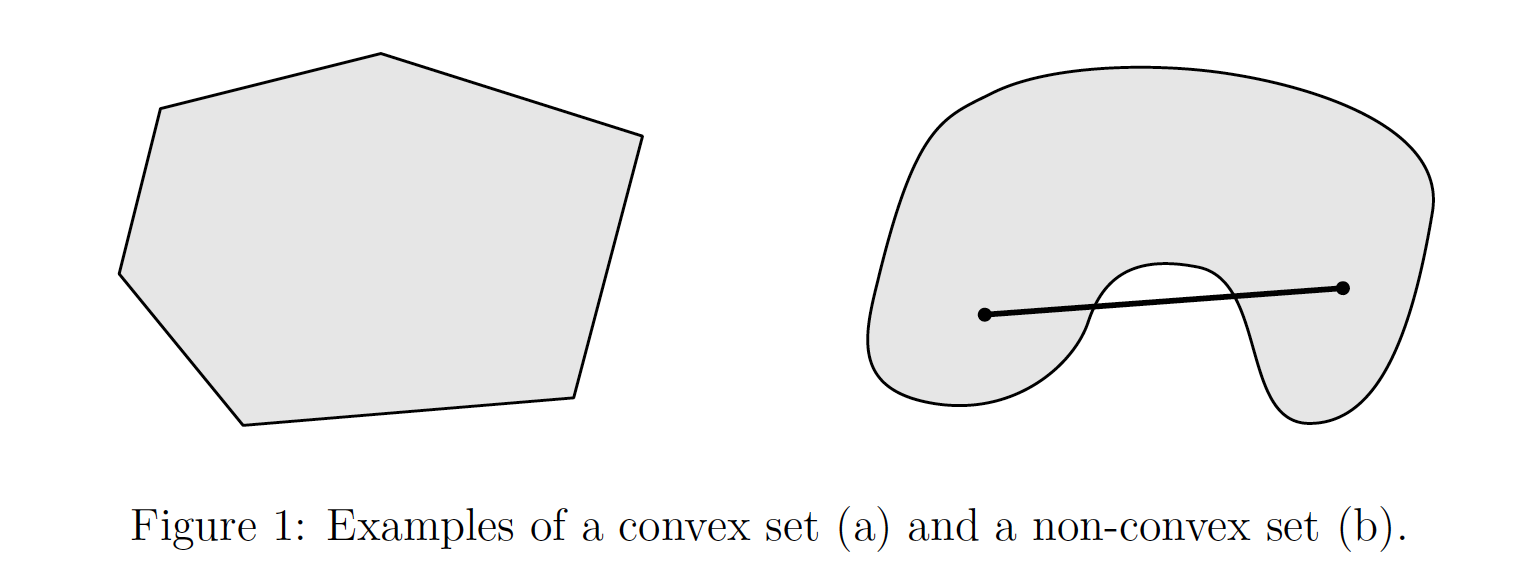
你可以看到,左图中任意两点,它们的线段一定会在C这个集合中,所以它就是一个凸集,但是对于右图而言,其线段就可能会有部分不在集合中,因此它不是凸集。
如果我们用数学定义来描述凸集的话,它是指这样的一个集合$C$:对任意$x,y \in C, \Theta \in R, 0 \leq \Theta \leq 1$,都有 $$\Theta x + (1-\Theta)y \in C \tag{2.1}$$
常见的凸集有,n维实数空间;一些范数约束形式的集合;仿射子空间;凸集的交集;n维半正定矩阵集。
凸函数
那么知道凸集是什么意思后,让我们看看凸函数。 凸函数的几何意义是,函数任意两点(x, y)连线上的值一定大于对应自变量区(x, y)间内的函数值(f(x),f(y)),示例图如下:

你可以看到,将xy连接起来的直线上的值,一定大于xy两点范围内的函数值$f(x)$
如果我们用数学定义来描述凸函数的话,凸函数$f(x)$是这样的一个函数:定义域为凸集$D(f)$,且对于任意$x,y \in D(f),\Theta \in R, 0 \leq \Theta \leq 1$,有 $$f(\Theta x + (1-\Theta)y) \leq \Theta f(x) + (1-\Theta)f(y) \tag{2.2}$$
常见的凸函数有,指数函数族;非负对数函数;仿射函数;二次函数;常见的范数函数;凸函数非负加权的和等。
凸优化问题
讲解完凸集和凸函数的定义,终于到凸优化问题了。 凸优化问题,实际上就是研究定义于凸集中的凸函数最小化问题。 正式的说,凸优化问题在优化问题中的形式是这样的 $$\min \ f(x), \ \ s.t. x \in C \tag{2.3}$$ 其中$f$是一个凸函数,$C$为凸集,$x$是优化变量。 因为上面这个表达还是有些含糊,所以凸优化问题我们更常用这个形式来表示它 $$\min \ f(x), \ \ s.t. g_i(x) \leq 0, i = 1,…,m, h_i(x) = 0, i = 1,…,m \tag{2.4}$$ 其中$f$是一个凸函数,$g_i$是一个凸函数, $h_i$为仿射函数,$x$是优化变量。
常见的凸优化问题有,线性规划、二次规划、二次约束的二次规划、半正定规划。
二次规划
二次规划(Quadratic Programming,简称QP)是一类典型的优化问题,包括凸二次规划和非凸二次优化。在此类问题中,目标函数是变量的二次函数,而约束条件是变量的线性不等式。 假定变量个数为$d$,约束条件的个数是$m$,则标准的二次规划问题形如 $$min_x \frac{1}{2} x^TQx + c^Tx,\ s.t. Ax \leq b \tag{2.5}$$ 其中$x$为$d$维向量,$ Q\in R^{d \times d}$为实对称矩阵,$ A \in R^{m \times d}$为实矩阵,$b \in R^m$和$c \in R^d$为实向量,$Ax \leq b$的每一行对应一个约束。
通常一个优化问题可以从两个角度来考虑,即主问题(primal problem)和对偶问题(dual problem)。在约束最优化问题中,常常利用拉格朗日对偶性将原始问题(主问题)转换成对偶问题,通过解对偶问题来得到原始问题的解。这样做是因为对偶问题的复杂度往往低于主问题。
$$min_{\omega,b}\frac{1}{2}||\omega||^2,\ s.t. y_i(\omega^Tx_i+b) \geq 1, i = 1,2,…,m \tag{1.7}$$ 在求解SVM的时候,我们也会通过其拉格朗日对偶性,将该主问题$式(1.7)$转换成对偶问题,然后进行求解。
需要说明的是,因为主问题本身是一个凸二次规划问题,因此它是能直接用现成的优化计算包求解的,使用拉格朗日乘子法得到其对偶问题是为了优化运算效率。
拉格朗日乘子法
拉格朗日乘子法(Largrange multipliers)是一种寻找多元函数在一组约束下的极值的方法。通过引入拉格朗日乘子,可将有$d$个变量与$k$个约束条件的最优化问题转化为具有$d+k$个变量的无约束优化问题求解。 这样说你可能会觉得很抽象,那么让我们先举一个稍微简单一点的例子。
等式约束的优化问题
先考虑一个等式约束的优化问题,假定$x$为$d$维向量,我们想要寻找$x$的某个取值$x^*$,使得目标函数$f(x)$最小且同时满足$g(x)=0$的约束。从几何角度看,这个问题的目标是在方程$g(x)=0$确定的$d-1$维曲面上寻找能使目标函数最小化的点。如图所示

通过上面的描述,我们不难得到如下结论:
- 对于约束曲面上的任意点$x$,该点的梯度$\nabla g(x)$正交于约束曲面;
- 在最优点$x^*$,目标函数在该点的梯度$\nabla f(x^*)$正交于约束曲面;
由此可知,在最优点$x^*$,如上图所示,梯度$\nabla g(x)$和$\nabla f(x)$的方向必相同或相反,即存在$\lambda \neq 0$($\lambda$称为拉格朗日乘子)使得 $$\nabla f(x^*) + \lambda \nabla g(x^*) = 0 \tag{2.6}$$ 基于上面这个式子,我们可以定义拉格朗日函数 $$L(x,\lambda) = f(x) + \lambda g(x) \tag{2.7}$$
你可能会疑惑,为什么拉格朗日函数会是这个样子。那么让我们对这个函数进行求导看看:
- 当$L(x,\lambda)$对$x$求导时:(因为要求最优解,所以我们需要置$\nabla_x L(x, \lambda)$为0) $$\nabla_x L(x, \lambda) = \nabla f(x) + \lambda \nabla g(x) = 0 \tag{2.8}$$
- 当$L(x,\lambda)$对$\lambda$求导时:(我们同样置$\nabla_{\lambda} L(x, \lambda)$为0) $$\nabla_{\lambda} L(x, \lambda) = 0 + g(x) = 0 \tag{2.9}$$
注意,在一开始,我们的目标是寻找$x$的某个取值$x^*$,使得目标函数$f(x)$最小且同时满足$g(x)=0$的约束。 那么通过拉格朗日函数的两次对不同变量的求导,你可以发现
- 式(2.8) = 式(2.6),这是为了使得目标函数$f(x)$最小
- 式(2.9) = 约束条件$g(x)=0$,这是为了满足约束条件
因此,原约束优化问题就转化为了对拉格朗日函数$L(x, \lambda)$的无约束优化问题。
不等式约束的优化问题
现在考虑不等式约束$g(x) \leq 0$,如图B.1(b)所示,此时最优点$x^*$要么在$g(x) < 0 $的区域里,要么在边界$g(x) = 0$上。
- 对于$g(x)<0$的情形,约束$g(x) \leq 0$不起作用,可直接通过条件$\nabla f(x)=0$来获得最优点,这等价于将$\lambda$置0,然后对$\nabla_x L(x, \lambda)$置0得到最优点
- 对于$g(x)=0$的情形,类似于上面我们对等式约束的分析,但需注意的是,此时$\nabla f(x^*)$的方向必与$\nabla g(x^*)$相反,即存在常数$\lambda > 0$使得$\nabla f(x^*) + \lambda \nabla g(x^*) = 0$
对上面描述的两种情况进行整合,在约束$g(x) \leq 0$下最小化$f(x)$的任务,可以转化为在如下约束下最小化$L(x,\lambda) = f(x) + \lambda g(x)$的任务: $$\begin{cases}g(x) \leq 0\ \lambda \geq 0\ \lambda_j g_j(x) = 0\end{cases} \tag{2.10}$$
式(2.10)就是大名鼎鼎的Karush-Kuhn-Tucker(简称KKT)条件。
多个约束条件的优化问题
在对等式约束优化问题和不等式约束优化问题进行讲解后,我们可以将其推广到多个约束。 考虑具有$m$个等式约束和$n$个不等式约束,且可行域$D \subset R^d$非空的优化问题 $$min_x \ f(x),\ \ s.t. \ h_i(x)=0 \ (i = 1,…,m), \ g_j(x) \leq 0 \ (j = 1,…,m) \tag{2.11}$$ 引入拉格朗日乘子$\lambda = (\lambda_1, \lambda_2, …, \lambda_m)^T$和$\mu = (\mu_1,\mu_2,…,\mu_n)^T$,相应的拉格朗日函数为 $$L(x,\lambda, \mu) = f(x) + \sum_{i=1}^m \lambda_i h_i(x) +\sum_{j=1}^n \mu_j g_j(x) \tag{2.12}$$ 由不等式约束引入的KKT条件(j=1,2,…,n)为 $$\begin{cases}g_j(x) \leq 0\ \mu_j \geq 0\ \mu_j g_j(x) = 0\end{cases} \tag{2.13}$$
SVM的拉格朗日函数
好了好了,我想看了前面那么多推导,你可能已经想捶我了。(逃 其实前面说那么多,都是为了这部分做铺垫,那么让我们来看看如何得出SVM的拉格朗日函数吧! 首先回顾一下SVM基本式的公式—— $$min_{\omega,b}\frac{1}{2}||\omega||^2,s.t. y_i(\omega^Tx_i+b) \geq 1, i = 1,2,…,m \tag{1.7}$$ 我希望现在你能一眼发现,它和前面式(2.11)的相似之处。 你可以看到,对于SVM基本式而言,其——
- $f(\omega, b) = \frac{1}{2}||\omega||^2$
- $g(\omega, b) = 1-y_i(\omega^Tx_i+b) \leq 0,i=1,2,…,m.$
- $h(\omega, b) = 0$
因此,我们将SVM的$f(\omega, b)、g(\omega, b)、h(\omega, b)$代入式(2.12)中后,就可以得到该问题的拉格朗日函数了,即 $$L(\omega,b, \alpha) = \frac{1}{2}||\omega||^2 + \sum_{i=1}^m \alpha_i (1-y_i(\omega^Tx_i + b)) \tag{2.14}$$ 其中$\alpha = (\alpha_1; \alpha_2;…;\alpha_m)$,拉格朗日乘子$\alpha_i \geq 0$。
对偶问题
前面我们说过,一个优化问题可以从两个角度来考虑,即主问题(primal problem)和对偶问题(dual problem)。在约束最优化问题中,常常利用拉格朗日对偶性将原始问题(主问题)转换成对偶问题,通过解对偶问题来得到原始问题的解。这样做是因为对偶问题的复杂度往往低于主问题。
多约束对偶问题
在讲解SVM的对偶问题之前,我们先来看一下多约束对偶问题的通用解。
- 多约束对偶问题的主问题: $$min_x \ f(x),\ \ s.t. \ h_i(x)=0 \ (i = 1,…,m), \ g_j(x) \leq 0 \ (j = 1,…,m) \tag{2.11}$$
- 其相应的拉格朗日函数为 $$L(x,\lambda, \mu) = f(x) + \sum_{i=1}^m \lambda_i h_i(x) +\sum_{j=1}^n \mu_j g_j(x) \tag{2.12}$$
基于(2.12),对主问题(2.11)的拉格朗日对偶函数$\Gamma: R^m \cdot R^n \rightarrow R$定义为 $$\Gamma(\lambda,\mu) = inf_{x \in D} L(x,\lambda,\mu) = inf_{x \in D} (f(x) + \sum_{i=1}^m \lambda_i h_i(x) +\sum_{j=1}^n \mu_j g_j(x)) \tag{3.1}$$ 若$\tilde{x} \in D$为主问题(2.11)可行域中的点,则对任意$\mu \geq 0$和$\lambda$都有 $$\sum_{i=1}^m \lambda_i h_i(x) + \sum_{j=1}^n \mu_j g_j(x) \leq 0 \tag{3.2}$$ 进而有 $$\Gamma(\lambda,\mu) = inf_{x \in D} L(x,\lambda,\mu) \leq L(\tilde{x},\lambda,\mu) \leq f(\tilde{x}) \tag{3.3}$$
若主问题(2.11)的最优值为$p^*$,则对任意$\mu \geq 0$和$\lambda$都有 $$\Gamma(\lambda,\mu) \leq p^* \tag{3.4}$$ 即对偶函数给出了主问题最优值的下界。显然,这个下界取决于$\mu$和$\lambda$的值。于是一个很自然的问题就是:基于对偶函数能获得的最好下界是什么?这就引出了优化问题 $$max_{\lambda, \mu} \Gamma(\lambda, \mu) \ \ s.t. \mu \geq 0 \tag{3.5}$$
式(3.5)就是主问题(2.11)的对偶问题,其中$\mu$和$\lambda$称为对偶变量(dual variable)。无论主问题(2.11)的凸性如何,对偶问题(3.5)始终是凸优化问题。
考虑式(3.5)的最优值$d^*$,显然有
- $d^* \leq p^*$,这称为“弱对偶性(weak duality)”成立;
- 若$d^* = p^*$,则称为“强对偶性(strong duality)”成立,此时由对偶问题能获得主问题的最优下界;
对于一般的优化问题,强对偶性通常不成立,但是若主问题是凸优化问题,如式(2.11)中$f(x)$和$g_j(x)$均为凸函数,$h_i(x)$为仿射函数,且其可行域中至少有一点使不等式约束严格成立,则此时强对偶性成立。
P.S. 在强对偶性成立时,将拉格朗日函数分别对元变量和对偶变量求导,再同时令导数等于0,即可得到原变量与对偶变量的数值关系。 于是对偶问题解决了,主问题也就解决了。
SVM的对偶问题
那么让我们回顾一下
- SVM的主问题 $$min_{\omega,b}\frac{1}{2}||\omega||^2,s.t. y_i(\omega^Tx_i+b) \geq 1, i = 1,2,…,m \tag{1.7}$$
- SVM的拉格朗日函数 $$L(\omega,b, \alpha) = \frac{1}{2}||\omega||^2 + \sum_{i=1}^m \alpha_i (1-y_i(\omega^Tx_i + b)) \tag{2.14}$$ 其中$\alpha = (\alpha_1; \alpha_2;…;\alpha_m)$,拉格朗日乘子$\alpha_i \geq 0$。
你可以发现,SVM恰恰满足了前面我们所说的强对偶性。 因此,考虑令$L(\omega,b, \alpha)$对$\omega$和$b$的偏导为0可得 $$\omega = \sum_{i=1}^m \alpha_i y_i x_i \tag{3.6}$$ $$0 = \sum_{i=1}^m \alpha_i y_i \tag{3.7}$$ 将式(3.6)代入(2.14),就可以将$L(\omega,b, \alpha)$中的$\omega$和$b$消去,再考虑式(3.7)的约束,就得到式(2.14)的对偶问题。 $$max_{\alpha} \sum_{i=1}^m \alpha_i - \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^m \alpha_i \alpha_j y_i y_j x_i^T x_j \tag{3.8}$$ $$s.t. \sum_{i=1}^m \alpha_i y_i = 0, \alpha_i \geq 0, i=1,2,…,m$$
求解模型
解出$\alpha$后,求出$\omega$和$b$即可得到模型 $$f(x) = \omega^T x + b = \sum_{i=1}^m \alpha_i y_i x_i^Tx + b \tag{4.1}$$ 从对偶问题(3.8)解出的$\alpha_i$是式(2.14)中的拉格朗日乘子,它恰好对应着训练样本$(x_i,y_i)$。因为式(1.7)中有不等式约束,因此上述过程还需满足KKT条件,即 $$\begin{cases}\alpha_i \geq 0\ y_i f(x_i)-1 \geq 0\ \alpha_i(y_i f(x_i)-1) = 0\end{cases} \tag{4.2}$$
于是,对任意训练样本$(x_i,y_i)$,总有$\alpha_i=0$或$y_i f(x_i)=1$。
- 若$\alpha_i = 0$,则该样本将不会在式(4.1)的求和中出现,也就不会对$f(x)$产生任何影响;
- 若$\alpha_i > 0$,则必有$y_i f(x_i)=1$,所对应的样本点位于最大间隔边界上,是一个支持向量。
这显示出支持向量机的一个重要性质: 训练完成后,大部分的训练样本都不需保留,最终模型仅与支持向量有关。
那么如何求解式(3.8)呢? 不难发现,这是一个二次规划问题,可使用通用的二次规划算法来求解,这一部分可以参考刚才对【二次规划】的讲解,除此之外,还可以使用SMO等算法对其进行求解。
References
[1] 机器学习.周志华
[2] Stanford CS229 Machine Learning的教学资料:http://cs229.stanford.edu/section/cs229-cvxopt.pdf

